In the field of natural language processing (NLP), the Transformer architecture has revolutionized the way machines understand and generate human language. Introduced by Vaswani et al. in 2017, Transformers have become the foundation for many state-of-the-art models, including BERT, GPT, and T5. This blog explores the key components and principles of Transformer architecture and its impact on linguistics.
Historical Background
The Transformer architecture was introduced in the paper "Attention is All You Need" by Vaswani et al. in 2017. Prior to Transformers, models like RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory networks) were popular for sequence-to-sequence tasks. However, these models faced limitations in handling long-range dependencies and parallelization. Transformers addressed these issues with a novel approach to sequence modeling.
Core Components of Transformer Architecture
The Transformer model is built on several key components:
1. Self-Attention Mechanism: This mechanism allows the model to weigh the importance of different words in a sentence when encoding a word. It captures relationships between words regardless of their distance in the sequence.
2. Positional Encoding: Since Transformers do not process sequences in order, positional encoding is added to provide information about the positions of words in the sequence. This helps the model understand the order and position of words.
3. Multi-Head Attention: This component uses multiple attention heads to focus on different parts of the sentence simultaneously. It allows the model to capture various aspects of the relationship between words.
4. Feed-Forward Neural Networks: After the attention mechanism, the model passes the data through feed-forward neural networks to transform the input into a higher-level representation.
5. Encoder-Decoder Structure: The Transformer architecture consists of an encoder and a decoder. The encoder processes the input sequence, while the decoder generates the output sequence.
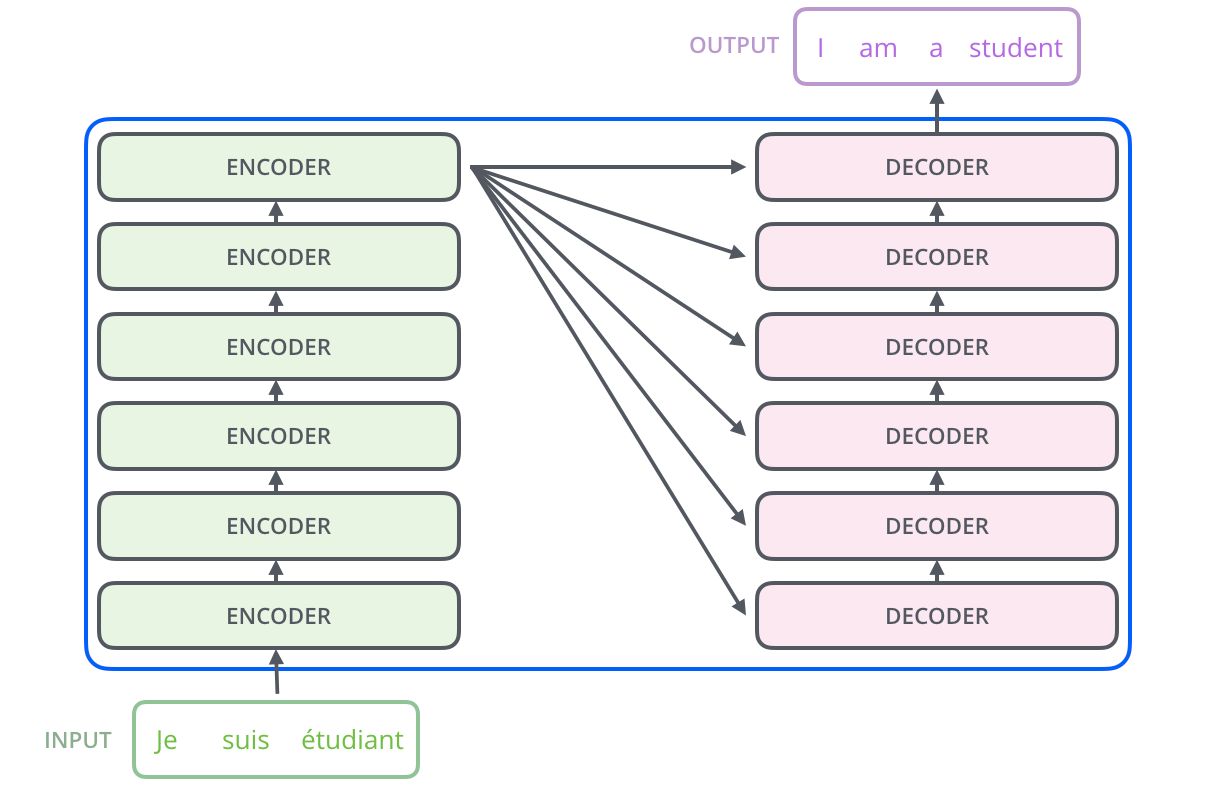
Key Advantages
The Transformer architecture offers several advantages over previous models:
1. Parallelization: Unlike RNNs, Transformers can process all words in a sequence simultaneously, significantly speeding up training and inference.
2. Long-Range Dependencies: The self-attention mechanism allows Transformers to capture long-range dependencies effectively, improving the understanding of complex sentences.
3. Scalability: Transformers can be scaled up to handle larger datasets and more complex tasks, making them suitable for a wide range of applications.
Applications in Linguistics
Transformers have had a profound impact on various linguistic tasks:
1. Machine Translation: Transformers have set new benchmarks in machine translation, providing more accurate and fluent translations.
2. Text Generation: Models like GPT (Generative Pre-trained Transformer) leverage Transformers to generate coherent and contextually relevant text.
3. Sentiment Analysis: Transformers can analyze sentiment in text with high accuracy, benefiting applications in customer feedback and social media monitoring.
4. Named Entity Recognition: Transformers improve the identification of entities such as names, dates, and locations in text, enhancing information extraction tasks.
Challenges and Future Directions
Despite their success, Transformers face challenges such as high computational requirements and the need for large amounts of training data. Research is ongoing to address these issues and further improve the efficiency and effectiveness of Transformer models.
Conclusion
The Transformer architecture has transformed the field of natural language processing, offering powerful tools for understanding and generating human language. Its innovative components and superior performance have made it the backbone of many modern NLP applications. As research continues to advance, Transformers will likely play an even more significant role in the future of linguistics and artificial intelligence.